
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- ETRI
- hadoop
- 한국전자통신연구원 인턴
- kt aivle school
- 딥러닝
- 서평
- SQL
- 소셜네트워크분석
- python
- ggplot2
- kaggle
- 시각화
- 빅분기
- KT 에이블스쿨
- dx
- 에이블러
- matplot
- 기계학습
- 하둡
- 시계열
- 에이블스쿨
- 한국전자통신연구원
- 하계인턴
- ML
- 지도학습
- arima
- KT AIVLE
- Ai
- Eda
- SQLD
- cnn
- 웹크롤링
- 머신러닝
- r
- 에트리 인턴
- 가나다영
- 빅데이터분석기사
- 다변량분석
- httr
- 프로그래머스
- Today
- Total
소품집
[ML] A Motion Sensor Data - User Activity 맞추기 본문
0. Data domain
https://github.com/mmalekzadeh/motion-sense
GitHub - mmalekzadeh/motion-sense: MotionSense Dataset for Human Activity and Attribute Recognition ( time-series data generated
MotionSense Dataset for Human Activity and Attribute Recognition ( time-series data generated by smartphone's sensors: accelerometer and gyroscope) (PMC Journal) (IoTDI'19) - GitHub - mmale...
github.com
A_DeviceMotion_data
- 12개 feature
- 6개 행동정보 (downstairs, upstairs, walking, jogging, sitting, standing)
- 50Hz sample rate
1. 문제 정의
그림1.은 Raw Dataset에서 피크 통계량, 파고율, 변화분석을 통해 생성한 feature로 RF 모델의 성능을 얻은 결과값이다.
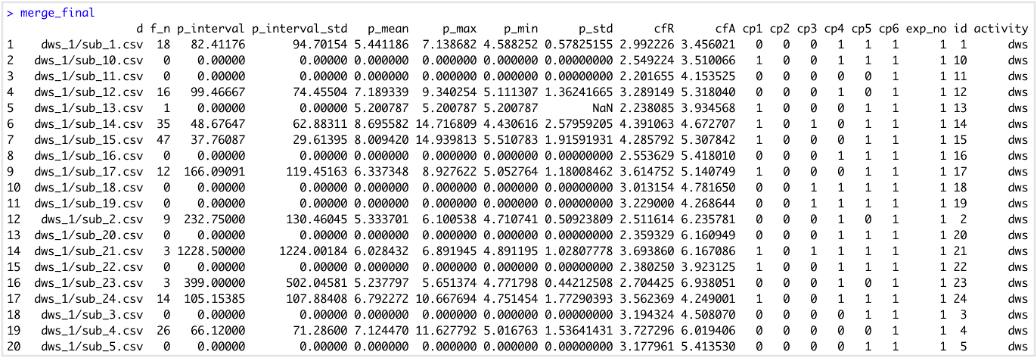
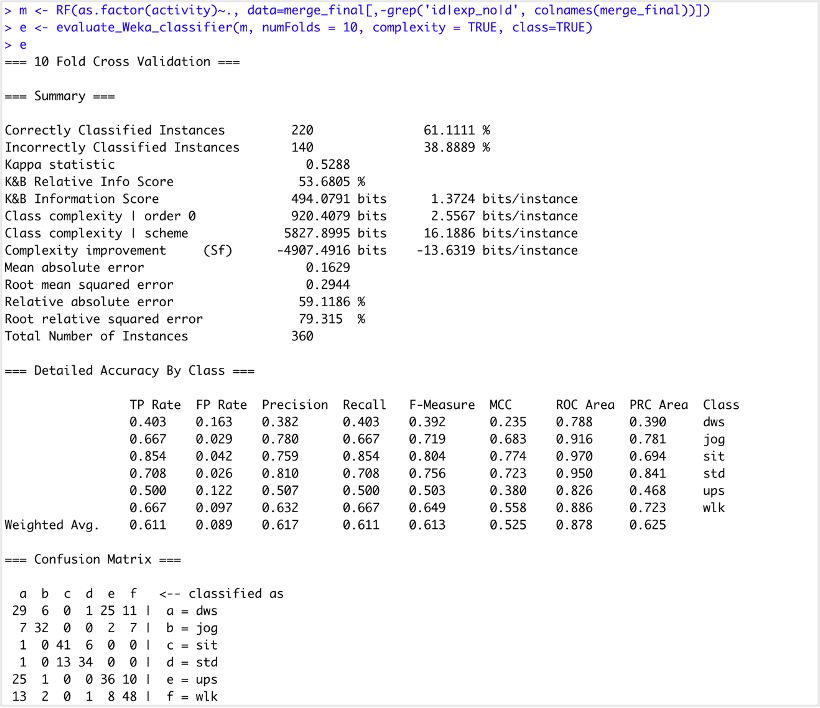
그림1. 전체 데이터 분석 RF 성능
Data set에서 더 다양한 feature를 뽑아 RF 알고리즘을 이용하여 모델 정확도 성능을 올리는 것이 목표이며, 기초 통계량을 feature로 넣기 전 성능은 60% 내외이다.
먼저 다양한 feature를 생성하기 이전에, 그림1. RF 모델의 confusion matrix를 확인한 결과 dws와 ups를 잘 구분하지 못하는 것으로 확인했다. 따라서 두 class를 잘 분류할 수 있도록 다양한 feature를 생성하여 모델 성능을 높여볼 것이다.
2. 데이터 파일 로드
분석에 사용된 휴대폰 센서 데이터는 GitHub Open Souce 데이터이며, 12개의 feature와 사람의 Activity(downstairs, upstairs, walking, jogging, sitting, standing)를 구분해 파일명으로 확인할 수 있다.



그림2. mag function을 적용한 myfread 함수 생성 및 전체 데이터 로드
그림2.는이번 과제에서는 data.table 라이브러리에 내장 되어있는 fread 함수를 사용하여 보다 빠른 속도로 데이터를 불러왔고, 기존 enviroment에 360개 파일을 올려 두고 파일을 합치는 방법이 아닌, 불러 오면서 하나의 데이터 셋으로 합쳤다.
또한 myfread 함수를 만들어 파일에서 뽑을 수 있는 정보인 exp_no, id, activity feature를 추가했다. 그리고 userAcceleration, rotationRate, gravity 총 3개의 feature에 mag 함수를 적용하여 전체 fls 파일에 새로운 feature로 만들어 HAR_total 데이터 프레임을 생성했다. 특히 Maggravity feature의 summary 값은 Min 0.098 Max 1의 값으로 대부분 1에 가까운 값을 확인했고, class 분류 성능에 도움이 되는 feature가 아니라고 판단했다.
2-1. 기초 통계 feature 생성
먼저 기초 통계량 mean, min, max, sd, rms, rss, skewness, IQR 총 9개의 feature를 추가하여 RF 모델의 성능을 확인했다.

그림3. 9개의 기초 통계량을 feature로 추가한 모델의 결과
그림3.의 9개의 기초 통계량을 추가한 모델의 결과, Total Number of Instances가 360개에서 53개로 줄은 것을 확인했다. 이 문제를 확인해 보기 위해 기초 통계량 함수를 살펴보았고, 그 결과 skewness 함수에서 instances NAN 값에 대한 예외처리가 되어 있지 않아 생긴 문제였다. 따라서 skewness 함수는 모델의 Total Instances에 영향을 주는 요소로 파악되어 제외하고 다시 모델 성능을 확인했다.

그림4. Skewness를 제외한 모델의 결과
그림4.의 모델 정확도를 확인한 결과 Total Number Instances가 360개로 유지되었다. 또한 테스트 모델 성능은 87.22%로 기초통계만으로도 Class Activity를 잘 분류하는 것으로 파악했다.
Confusion Matrix의 결과 여전히 그림1.에서 정의한 문제였던 dws와 ups Class Activity를 잘 구분하지 못하는 것으로 확인했다.
2-2. diff variable 생성
연속하는 센서 데이터의 before와 after 사이의 diff 값을 기반으로 diff Variable을 생성했고, 생성한 diff 함수는 총 4개로, diff Min, Max, Mean, Sum이 있다.

그림5. diff 함수를 적용한 모델의 결과
그림5.의 diff variable을 추가한 RF 모델 성능을 확인해보았다. 모델 정확도를 확인한 결과 85.556%로 추가하기 이전의 그림4.의 정확도보다 낮아진 것을 확인했고, diff 기초 통계 함수는 Class 분류에 큰 차이를 보이지 않는 다는 것을 확인했다.
2-3. Entropy(엔트로피) variable 생성
머신러닝 모델 feature를 정의하기 위해 가장 많이 사용하는 방법인 Entropy 값을 계산하는 것이다. 엔트로피(Entropy)는 주어진 데이터 집합의 혼잡도를 의미하며, 서로 다른 종류의 값이 섞여 있으면 정보 함유량이 높아 다음 분기 때 분류해야 할 클래스가 늘어나 엔트로피가 낮아진다.
엔트로피 함수를 적용한 variable은 'maguserAcceleration', 'magrotationRate','attitude.roll', 'attitude.pitch', 'attitude.yaw' 총 5개이다. ‘maggravity’ variable도 Entropy 함수를 적용해보았으나, 최소 0.998 최대 1.00으로 행동 class를 구분하는데 좋지 않은 feature라 판단했고, 성능 또한 하락하여 제외했다.

그림6. Entropy, diffEntropy 함수를 적용한 모델의 결과
그림6.은 Entropy, diffEntropy 함수를 적용한 feature의 결과이다. 모델 정확도는 92.22%로 실험자의 행동 Activity class를 높은 성능으로 분류하는 것으로 확인했다. 또한 그림1.에서부터 문제였던 dws와 ups class가 Entropy, diffEntropy feature를 통해 dws와 ups를 구분하는 class 변별력이 높아진 것을 확인했다.

그림7. Entropy 함수를 적용한 모델의 결과
그림7.은 diffEntropy 함수를 제외하고 적용한 feature의 결과이다. 모델의 성능이 93.0556% 까지 상승한 것으로 확인했다.
3. 시각화 EDA


그림8. Jog와 wlk 시계열 시각화
또한 기초 통계량 데이터만으로도 jog와 wlk를 잘 구분 지을 수 있는 이유는 max를 적용한 mag feature 값의 차이로 파악할 수 있었다. 반면 dws와 ups를 잘 구분할 수 없는 이유는 이 반대와 같은 상황이기 때문이다.
4. Raw Dataset으로 feature를 생성하여 정확도 비교하기
사용자의 움직임에 따라 수집되는 자이로 센서, 모션센서, 중력가속도 센서 등은 x, y, z 좌표별로 데이터를 수집한다. 그래서 mag 함수로 각 센서의 크기를 구하여 feature로 만들어서 RF 모델 성능을 확인했다. 이번에는 센서의 크기를 가공하지 않고 Raw Dataset에서 통계 feature를 계산해 두 모델을 비교하려한다.

그림9. Raw Dataset으로 통계 feature 생성
그림9.의 RF 모델의 성능은 98.889%로 Raw Dataset에 통계와 Entropy 함수로도 각 실험자의 행동 Activitty를 분류할 수 있는 것으로 확인됐다. 따라서 센서의 크기를 가공하지 않고 Raw Dataset에서 통계 feature를 사용해도 모델 성능 향상에 도움을 준다.
5. 코드
https://dayeong1021.notion.site/full-code-194fd2c73710410081c528002786bb53
'AI' 카테고리의 다른 글
| [ML] MIMIC-II 데이터 기반 패혈증 환자 분류 (0) | 2022.09.17 |
|---|---|
| [ML] MIMIC -III 중환자실 빅데이터 DEMO (0) | 2022.09.17 |
| [DL] Reinforcement Learning (Q-learning, Q-network..) (0) | 2021.11.12 |
| [DL] CNN 입출력, 파라미터 계산 (0) | 2021.10.06 |
| [DL] CNN, Convolution Neural Network 요약 (0) | 2021.10.01 |


