
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- cnn
- 프로그래머스
- python
- 하계인턴
- hadoop
- 하둡
- arima
- 빅데이터분석기사
- ETRI
- kt aivle school
- 웹크롤링
- SQLD
- ML
- Ai
- 지도학습
- 머신러닝
- 기계학습
- 가나다영
- KT AIVLE
- 빅분기
- 다변량분석
- dx
- 서평
- 에이블러
- Eda
- httr
- 한국전자통신연구원
- ggplot2
- 시계열
- 에트리 인턴
- 한국전자통신연구원 인턴
- 에이블스쿨
- 소셜네트워크분석
- SQL
- r
- kaggle
- 시각화
- 딥러닝
- KT 에이블스쿨
- matplot
Archives
- Today
- Total
소품집
HADOOP - MapReduce 본문
728x90
1. MapReduce의 개념
맵리듀스란?
- HDFS에 분산 저장된 데이터에 스트리밍 접근을 요청하여 빠르게 분산처리하도록 고안된 프로그래밍 모델, 이를 지원하는 시스템
- 대규모 분산 컴퓨팅 혹은 컴퓨팅 환경에서 개발자가 대량의 데이터를 병렬로 분석할 수있음
- 개발자는 맵리듀스 알고리즘에 맞게 분석 프로그램을 개발하고, 데이터의 입출력과 병렬처리 등 기반 작업은 프레임워크가 알아서 처리해줌
맵리듀스 프로그래밍 모델의 처리 과정




맵리듀스의 처리과정 요약

2. MapReduce 아키텍처
동적 관점에서의 구성요소
- 태스크 (Task)
- 맵퍼나 리듀서가 수행하는 단위 작업 (맵 태스크, 리듀스 태스크)
- 맵 혹은 리듀스를 수행하기 위한 정보를 가지고 있음
- 맵퍼 (Mapper)
- 구성: 맵(Map), 컴바인(Combine), 파티션(Partition)
- 맵 동작 : 인풋 데이터를 가공하여 사용자가 원하는 정보를 Key-value 쌍으로 변환
- 리듀서 (Reducer)
-
구성: 셔플/정렬 (Shuffle/Sort), 리듀스(Reduce)
-
리듀서 동작
-가공된 Key-Value를 Key 기준으로 각 리듀서로 분배
-사용자가 정의한 방법으로 각 Key와 관련된 정보를 추출
-

매핑 프로세스
-
입력파일
- HDFS에 있는 입력 파일을 분할하여 FileSplit을 생성
- FileSPlit 하나 당 맵 태스크 (Map Task) 하나씩 생성
- 맵 (Map)
- 데이터를 읽어와서 KV 페어 (Key-Value pair)를 생성
- 컴바인 (Combine)
- KV 리스트 (Key-Value list)에 대한 전처리 수행
- 맵의 결과를 리듀서에 보내기 전에 데이터를 최소화 (데이터 전송량을 줄일 수 있음)
- 리듀스와 동일한 함수 사용 (But, 리듀스를 대체할 수 없다)
- 파티션 (Partition)
- Key를 기준으로 디스크에 분할 저장(해시(Hash) 파티셔닝 사용)
- 각 파티션은 키를 기준으로 정렬이 됨
- HDFS가 아닌 맵퍼의 Local File System에 저장

리듀싱 프로세스
- 셔플 (Shuffle)
- 여러 맵퍼에 있는 결과 파일을 각 리듀서에 할당
- 리듀서에 할당된 결과 파일을 리듀서의 로컬 파일 시스템으로 복사
- 정렬 (Sort)
- 병합 정렬(Merge sort)를 이용하여 맵퍼 결과 파일을 정렬/병합
- Key로 정렬된 하나의 커다란 파일이 생성됨
- 리듀스 (Reduce)
- 정렬 단계에서 생성된 파일을 처음부터 순차적으로 읽으면서 리듀스 함수를 수행

노드 관점에서의 구성 요소
클라이언트, 잡트래커, 태스크드래커로 구성

JobClient의 역할
- 입력 데이터의 분할 방침 결정
- 처리 대상 입력 데이터를 어떻게 분할하여 병렬 처리할지 결정
- JobTracker에게 MapReduce 잡 의뢰
- MapReduce 잡을 실행하기 위한 애플리케이션을 HDFS에 저장
- JobTracker로부터 진행상태를 수신
- 사용자 단위로 MapReduce 잡을 관리
- 잡의 우선순위 변경이나 잡을 강제 종료
JobTracker의 역할
- 잡 관리
- Map 태스크 할당 제어
- Map 처리 결과 파악
- JobClient에게 진행 통지
- 리소스 관리
- TackTracker에게 Map이나 Reduce처리 할당
- 처리의 주기적 실행
- 이상 발생시 처리 재할당
- 처리 실패 빈도가 높은 TackTracker 블랙리스트 생성
- TaskTracker 동작 여부 확인
- TaskTracker 추가/제외
- 잡 실행 이력 관리
TaskTracker의 역할
- Child 프로세스 생성과 처리 실행
- Child 프로세스 : Map이나 Reduce 작업을 동작시키는 자바 프로세스
- Child 프로세스에게 jar 파일이나 필요한 데이터를 전달
- Child 프로세스 상태 확인
- JobTracker로 부터 처리 중지 지시가 오면, 처리 중지를 통지
- Map처리 수와 Reduce 처리 수 파악
- JobTracker에게 주기적으로 하트비트 전송
- Map 또는 Reduce 동시 실행 가능한 슬롯 수 포함 (현재 빈 슬롯 수도)
데이터 플로우 - 맵 단계

데이터 플로우 - 셔플 단계
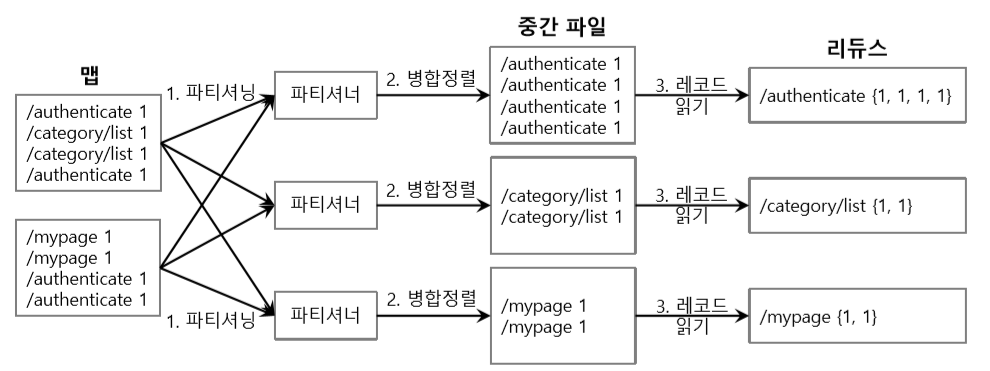
데이터 플로우 - 리듀스 단계

워크 플로우 - 잡 실행 요청

워크 플로우 - 잡 초기화

워크 플로우 - 태스크 할당

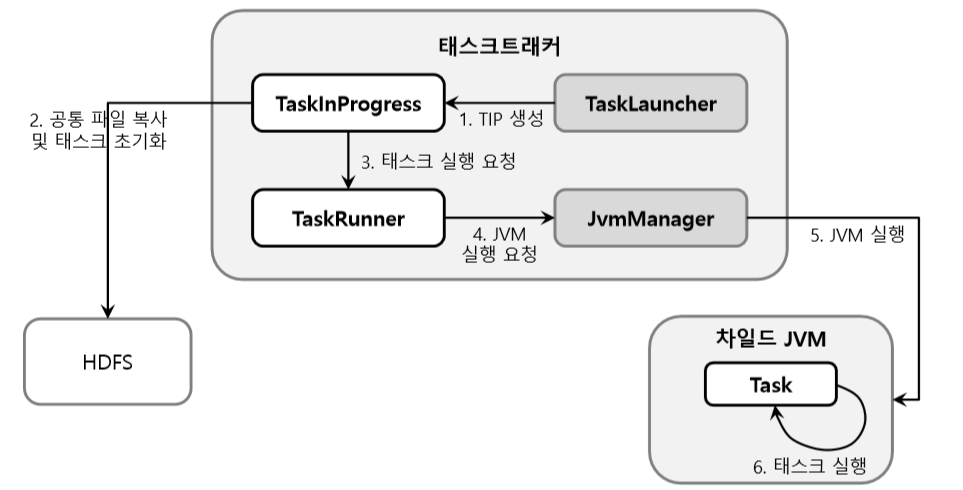
워크 플로우 - 태스크 실행
TaskInProgress 는 태스크의 상태를 모니터링 하는 제어정보
워크 플로우 - 잡 완료

3. MapReduce와 HDFS의 관계
데이터 분할
- Hadoop에서는 데이터를 HDFS에 저장
- MapReduce가 잡 처리시 HDFS에서 데이터를 읽고, 처리 결과를 HDFS에 저장
- 입력 데이터를 어떻게 분할하고 처리할지는 JobClient가 결정
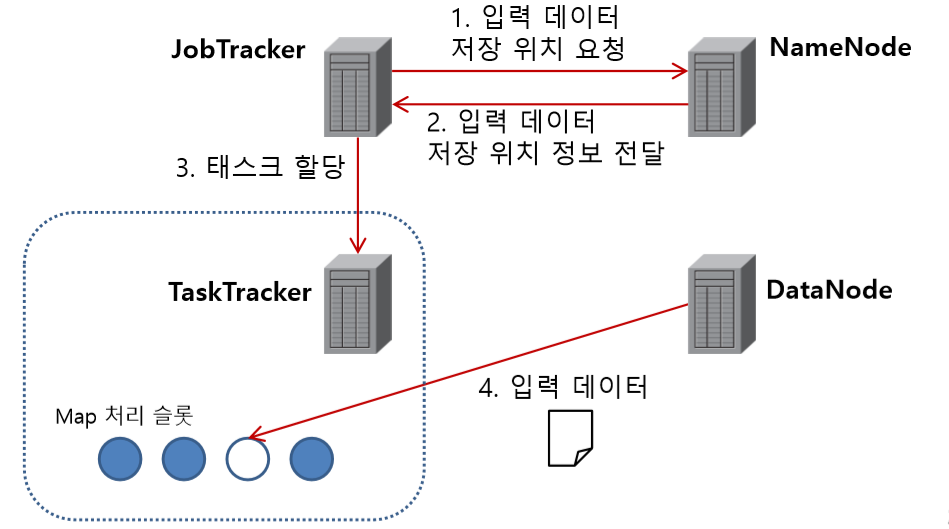
- 나의 Map 태스크는 하나의 스플릿(데이터 블럭)에서 레코드를 읽어 처리
데이터 지역성
- 가능한 한, 데이터를 동작하고 있는 처리 시스템으로 옮기는 것이 아니라, 처리 프로그램을 데이터가 있는 곳으로 이동
- 노드 간 데이터 전송량을 줄이고, 대량의 데이터를 처리하더라도 최대한 오버헤드가 발생하지 않도록 함 (저장된 위치에서 처리 되도록!)
- JobTracker는 NameNode와 소통해 가면서 태스크 할당
Map처리 할당
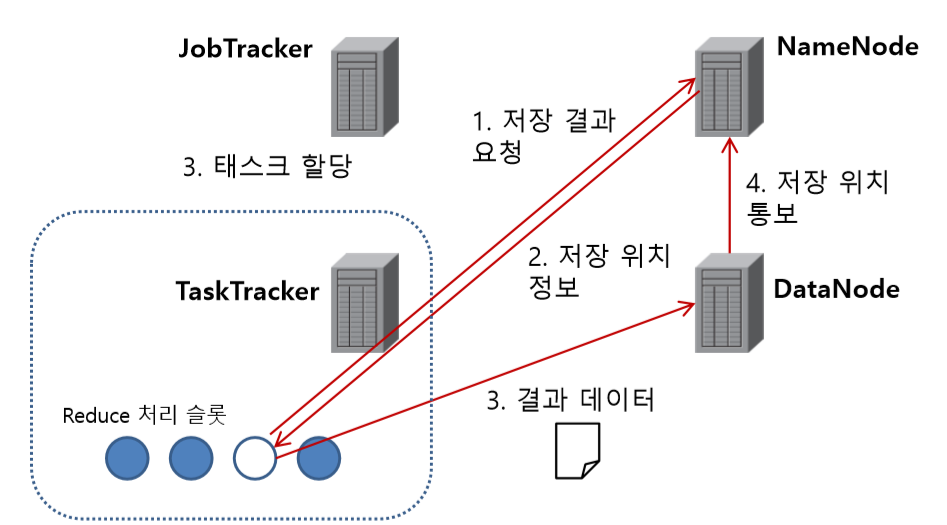
Reduce 처리 결과 기록
728x90
'Hadoop' 카테고리의 다른 글
| HDFS (Hadoop Distributed File System) (0) | 2020.05.12 |
|---|---|
| Hadoop 이란? 기본 동작구성과 프레임워크 (0) | 2020.05.12 |
| Hadoop 이란 (0) | 2020.04.01 |
'Hadoop' Related Articles
more



Comments