
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- arima
- hadoop
- 시계열
- httr
- ggplot2
- ML
- 기계학습
- 가나다영
- KT AIVLE
- 소셜네트워크분석
- 하계인턴
- 머신러닝
- 에이블러
- matplot
- 웹크롤링
- python
- 하둡
- 빅분기
- kt aivle school
- dx
- ETRI
- 한국전자통신연구원
- 에이블스쿨
- Ai
- 한국전자통신연구원 인턴
- KT 에이블스쿨
- SQLD
- Eda
- 빅데이터분석기사
- 프로그래머스
- 다변량분석
- r
- 에트리 인턴
- cnn
- 시각화
- 지도학습
- 서평
- kaggle
- 딥러닝
- SQL
- Today
- Total
소품집
[python] Session을 활용하여 크롤링 하기 본문
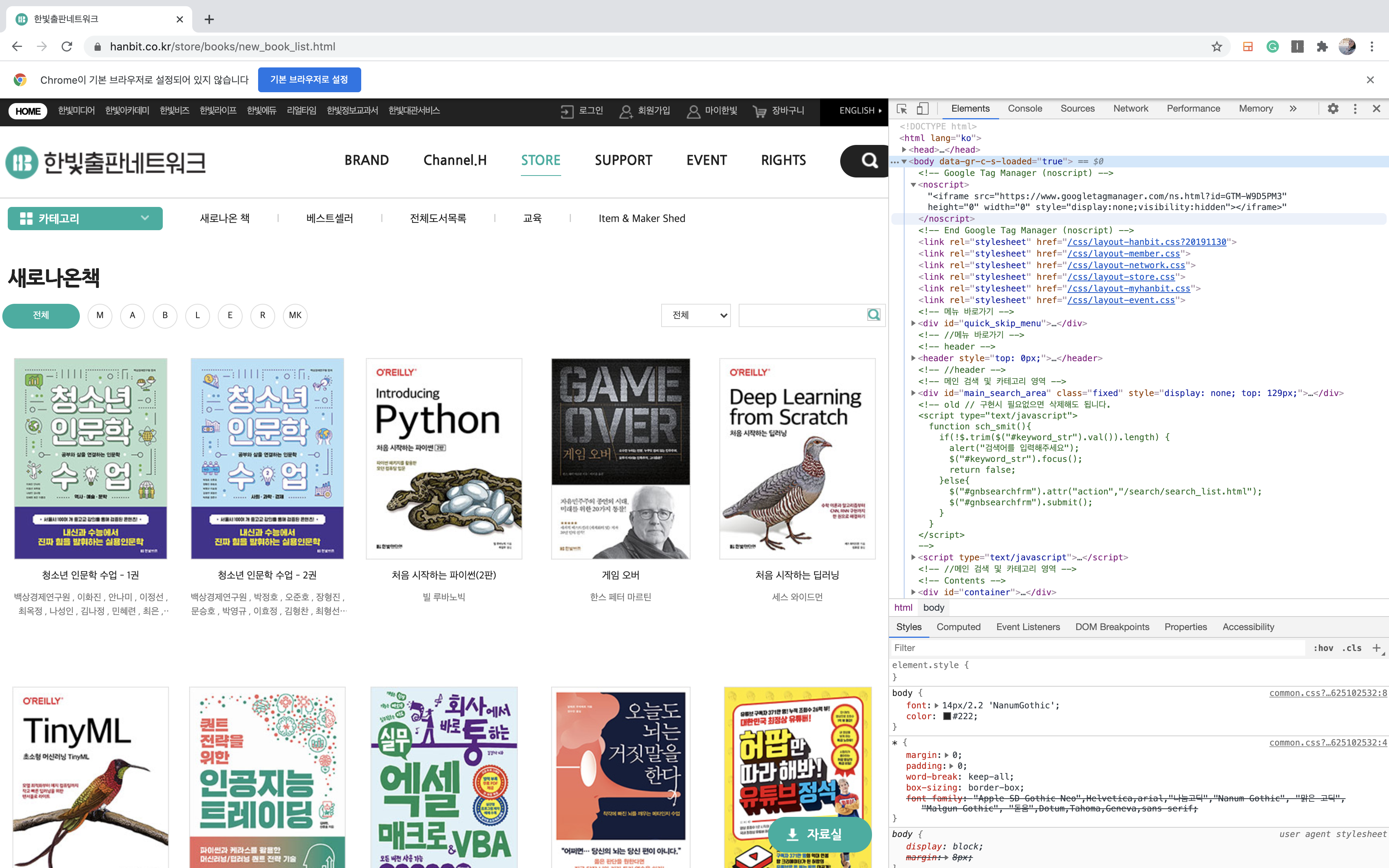
이번 실습에서는 한빛출판 네트워크 스토어 사이트에서 '새로나온 책' 목록을 크롤링 할 것입니다.
목록 페이지는 제목과 저자 정보를 추출할 예정이며전형적인 목록/상세 패
상세 페이지는 출간일, 페이지, ISBN, 물류 코드, 책 소개 등의 정보 중 제목, 가격, 목차 정보를 추출할 것입니다.
import time
import requests
import lxml.html
import re필요한 모듈을 불러와줍니다.
def main():
# 여러 페이지에서 크롤링을 위해 Session 사용
session = requests.Session()
# scrape_list_page() 함수를 호출해서 제너레이터를 추출
response = session.get('http://www.hanbit.co.kr/store/books/new_book_list.html')
urls = scrape_list_page(response)
for url in urls:
time.sleep(1) # 1초간 대기 - 블락을 예방하기 위해.
response = session.get(url) # Session을 사용해 상세 페이지를 추출
ebook = scrape_detail_page(response) # 상세 페이지에서 상세 정보를 추출
print(ebook) # 상세 정보 출력
break 목록 페이지에서 상세 페이지로 이동되는 링크 목록을 추출합니다.
- 전체 페이지 크롤링을 위해 main() 함수의 for 구문에서 break를 제거해줍니다.
- 서버에서 블락을 걸 경우의 수를 예상하여 time 모듈을 import 했는데요. time.sleep(1)를 추가해 1초간 대기시킵니다.
def scrape_list_page(response):
root = lxml.html.fromstring(response.content)
root.make_links_absolute(response.url)
for a in root.cssselect('.view_box .book_tit a'):
url = a.get('href')
yield url크롬에서 개발자 도구(F12)에서 css를 확인해가며 타이틀, 가격, 목차 태그를 긁어옵니다.
- response를 매개변수로 scrape_detail_page()를 호출하여 책의 상세 정보를 추출
- scrape_detail_page() 함수에서는 css selector를 사용해 스크래핑
- 제목과 가격은 root.cssselect() 함수로 추출한 리스트의 첫 번째 요소에서 문자열을 추출
- 목차는 List comprehension을 사용해 목차를 리스트로 추출
def scrape_detail_page(response):
"""
상세 페이지의 Response에서 책 정보를 dict로 추출
"""
root = lxml.html.fromstring(response.content)
ebook = {
'url': response.url,
'title': root.cssselect('.store_product_info_box h3')[0].text_content(),
'price': root.cssselect('.pbr strong')[0].text_content(),
'content': [normalize_spaces(p.text_content())
for p in root.cssselect('#tabs_3 .hanbit_edit_view p') # 길이가 0인 문자열이 아니면.
if normalize_spaces(p.text_content()) != ''] # 공백라인 제거
}
return ebookscrape_detail_page() 함수의 반환값은 list처럼 반복 가능한 제너레이트로 구현합니다.
# 목차에 포함돼 있는 공백을 제거할 수 있는 함수 정의
# 특정한 문자열을 바꿔줄 수 있는 함수로 생각해도 좋다.
def normalize_spaces(s):
"""
연결된 공백을 하나의 공백으로 변경
"""
return re.sub(r'\s+', ' ', s).strip()목차에 포함되어 있는 공백을 제거하기 위해 normalize_spaces() 함수를 정의하고,
List Comprehension 구문에 조건을 추가하여 빈 문자열을 제거합니다.
if __name__ == '__main__':
main()
결과값을 확인해봅니다.
'Web crawling' 카테고리의 다른 글
| ModuleNotFoundError: No module named 'MySQLdb' / 왜 안될까 왜 안될까 (0) | 2021.04.08 |
|---|---|
| [python] bs4 패키지를 이용해 네이버 날씨 crawling 연습해보기 (0) | 2021.04.05 |
| 소셜네트워크 분석 (0) | 2020.06.19 |
| 소셜네트워크 정의 및 igraph 패키지 사용하기 (2) | 2020.06.16 |
| Selenium을 크롬에서 구동하기 - 네이버카페 크롤링 (0) | 2020.05.11 |

