
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 빅분기
- 소셜네트워크분석
- python
- Ai
- 딥러닝
- KT AIVLE
- 한국전자통신연구원
- 빅데이터분석기사
- 한국전자통신연구원 인턴
- 웹크롤링
- arima
- matplot
- ggplot2
- 다변량분석
- r
- 머신러닝
- 하계인턴
- Eda
- cnn
- httr
- SQLD
- hadoop
- 에트리 인턴
- 기계학습
- ETRI
- KT 에이블스쿨
- 가나다영
- dx
- kt aivle school
- 에이블스쿨
- kaggle
- 지도학습
- 에이블러
- 시계열
- 서평
- ML
- 프로그래머스
- SQL
- 하둡
- 시각화
Archives
- Today
- Total
소품집
[웹 크롤링] 웹크롤링 쿠키 이용 본문
728x90
Cookies 란?
- 쿠키란 웹 사이트에 방문했을 때 웹 서버가 클라이언트 컴퓨터에 저장해 놓은 파일을 의미
- 예를 들면 로그인 상태 유지, 쇼핑몰 장바구니와 같은 정보를 기록함
- 이 특징을 이용하면 웹 서버에 저장해 놓은 쿠키는 로그인 상태로 HTTP 요청이 가능해짐
실습 - 잡 플레닛
잡플래닛 - Jobplanet
채용정보부터 직장인이 직접 남긴 기업리뷰, 연봉정보, 면접후기, 복지정보, 기업분석까지
www.jobplanet.co.kr

!! 로그인을 하지 않아도 로그인 정보가 남아있는 '쿠키'로 데이터를 긁어와, 실습을 해보겠습니다.
# 패키지 적용
library(dplyr)
library(httr)
library(urltools)
library(rvest)
# 로그인 화면에서 HTTP 요청을 실행합니다
URL <- 'https://www.jobplanet.co.kr/users/sign_in'
res <- POST(url=URL,
body = list('user[email]'='dayeong1021@gmail.com',
'user[password]'='비번 치세요!!'))
print(x=res)
# 쿠키 설정
# 로그인 쿠키를 설정
myCookies <- set_cookies(.cookies = unlist(x=cookies(x=res)))
# 수집할 기업명을 지정
compNm <-'삼성화재해상보험'
# 기업리뷰를 확인할 수 있는 URI를 지정
URI <- 'https://www.jobplanet.co.kr/companies/30056/reviews/%EC%82%BC%EC%84%B1%ED%99%94%EC%9E%AC%ED%95%B4%EC%83%81%EB%B3%B4%ED%97%98'
# 쿠키 로그인 상태 유지
res <- GET(url=URI, config = list(cookies=myCookies))
print(res)

# 리뷰 count
reviewCnt <- res %>%
read_html() %>%
html_nodes(css='li.viewReviews a span.num.notranslate') %>%
html_text() %>%
as.numeric()
# 연봉 count
salaryCnt <- res %>%
read_html() %>%
html_nodes(css='li.viewSalaries a span.num.notranslate') %>%
html_text() %>%
as.numeric()
연습문제
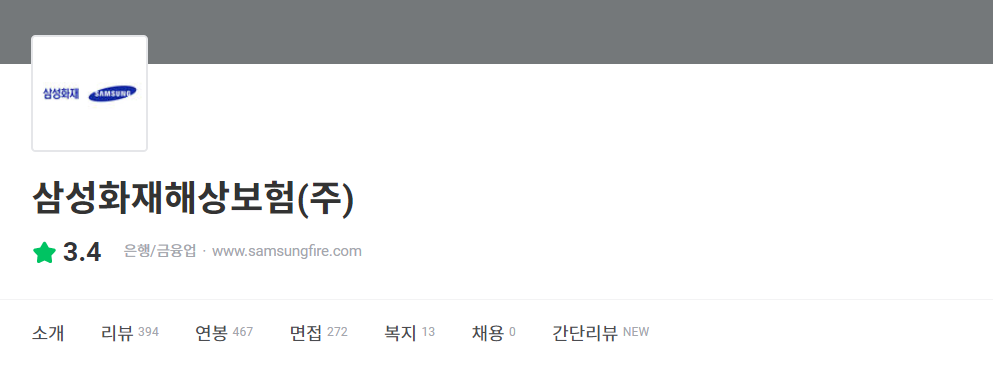
Q. 리뷰 이외에도 연봉, 면접, 복지 옆에 나와있는 count를 추출하여 하나의 벡터로 만들어보세요. (리뷰 개수 + 벡터 이름은 한글명으로)
A.
reviewCnt <- res %>%
read_html()%>%
html_nodes(css='span.num.notranslate') %>%
html_text() %>%
as.numeric()
reviewName <- res %>%
read_html() %>%
html_nodes(css='h2.txt') %>%
html_text()
names(reviewCnt) <- reviewName[-c(1,length(reviewName))]
728x90
'Web crawling' 카테고리의 다른 글
| [웹 크롤링] KOSPI 200 기업 (0) | 2020.04.25 |
|---|---|
| [웹 크롤링] JavaScript로 된 html 불러오기 (0) | 2020.04.13 |
| [웹 크롤링] 웹 크롤링 프로세스의 이해 (0) | 2020.04.09 |
| [웹 크롤링] 퍼센트 인코딩을 활용한 웹크롤링 실습 (0) | 2020.04.08 |
| [웹 크롤링] R로 네이버 실검 크롤링 하기 (0) | 2020.03.30 |
'Web crawling' Related Articles
more




Comments