
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 하계인턴
- 다변량분석
- matplot
- 시계열
- cnn
- 빅분기
- ML
- python
- KT AIVLE
- 프로그래머스
- 지도학습
- 서평
- 에이블스쿨
- r
- 한국전자통신연구원
- 딥러닝
- ETRI
- hadoop
- 웹크롤링
- Eda
- dx
- 소셜네트워크분석
- 에이블러
- 에트리 인턴
- 빅데이터분석기사
- kaggle
- 하둡
- Ai
- 가나다영
- httr
- KT 에이블스쿨
- 한국전자통신연구원 인턴
- 시각화
- arima
- SQL
- 머신러닝
- SQLD
- 기계학습
- ggplot2
- kt aivle school
Archives
- Today
- Total
소품집
주가 시계열 자료 분석 본문
728x90
주가 시계열 자료
Facebook 과 twitter 주식가격 활용

주식이 열린 시점부터 마감 된 시점까지의 변화량을 data.frame으로 나타낸 것 입니다. 이 중에서도 수정종가를 잘 봐야하는데요. 수정종가란 총 발행 주식수의 변화를 반영한 가격을 말합니다. (주식은 매일 가격이 변동되는 일정적이지 않은 값이기 때문에 그 값을 반영한 변화량이라 생각하면 됩니다.)
facebook.df <- read.csv("Stock_facebook.csv")
twitter.df <- read.csv("Stock_twitter.csv")
facebook.ts <- ts(facebook.df$Adj.Close, start = c(2015,8), frequency = 12)
twitter.ts <- ts(twitter.df$Adj.Close, start = c(2015,8), frequency = 12)먼저, data.frame 형태의 csv 파일을 읽어옵니다.
ts 함수 -> 기본값으로 저장하고, 반드시 start=, frequency= 옵션을 지정해 시계열을 생성합니다.
시계열 자료 생성하기, 불러오기
- 주가 시계열 자료
- Facebook 와 twitter 주식 가격 활용
- 일별 데이터 가져오기 : quantmod packages 활용
install.packages("quantmod")
library(quantmod)
#일별 데이터 가져오기
getSymbols("FB", src="yahoo", from=as.Date("2015-08-1"),to=as.Date("2018-08-31"))
getSymbols("TWTR", src="yahoo", from=as.Date("2015-08-1"),to=as.Date("2018-08-31"))quantmod 패키지는 일별 데이터를 가져올 때 사용하는 패키지 입니다.
시계열 그리기

# data.frame 불러오기
unemploy.df <- read.csv("BOK_unemployment_rate.csv")
oil.df <- read.csv("BOK_energy_oil.csv")
exchange.df <- read.csv("BOK_exchange_rate_krw_usd.csv")
# ts (시계열 타입으로 변환)
unemploy.ts <- ts(unemploy.df$unemployment_rate, start=2000,frequency = 1)
oil.ts <- ts(oil.df$oil,start = c(1994,1),frequency = 12)
exchange.ts <- ts(exchange.df$exchange_rate_krw_usd, start = c(1980,1),frequency = 4)
# plot
par(mfrow=c(2,2)) #2,2분면으로 나누기
plot(FB$FB.Adjusted,xlab="Time(daily)", ylab="Adjusted Price", main="Facebook")
plot(oil.ts, xlab="Time(Monthly)", ylab="Petolem consumption", main="korean")
plot(exchange.ts,xlab="Time(Quarterly)", ylab="Exchange rate", main="Exchange")
plot(unemploy.ts,xlab="Time(Yearly)", ylab="Adjusted Price", main="korean")
시계열 자료 계절주기 변환
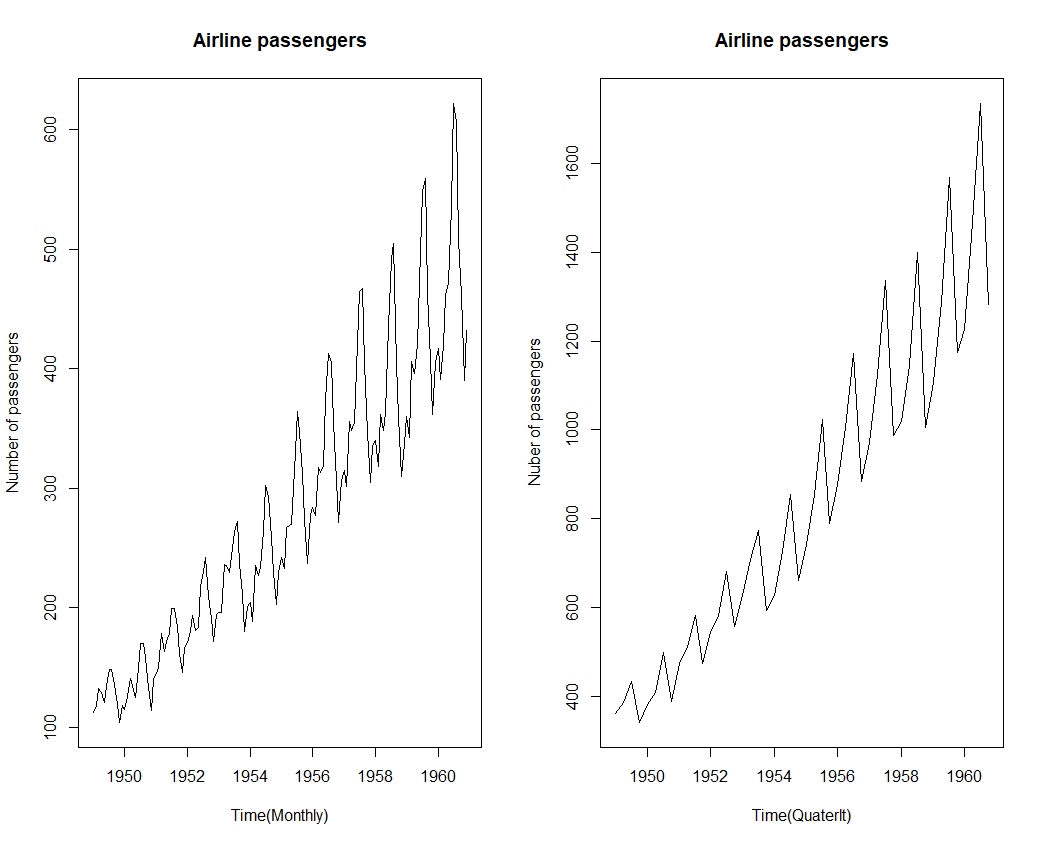
- 월별 자료를 분기별 자료로 변환 (합산)
- 월별 -> 분기별로 변환 된 그래프를 보니, 보다 스무스 해진 형태를 보이는 것을 알 수 있습니다.
# AirPassengers Data
AirPassengers
# 월별 자료를 분기별 자료로 변환하여 합산
air_quaterly <- aggregate(AirPassengers,nfrequency = 4, FUN=sum)
par(mfrow=c(1,2))
plot(AirPassengers,xlab="Time(Monthly)",ylab="Number of passengers", main ="Airline passengers")
plot(air_quaterly, xlab="Time(Quaterlt)", ylab= 'Nuber of passengers', main="Airline passengers")

- 월별 자료를 연도별 자료로 변환
- 월별 -> 연도별로 변환 된 그래프를 보니, 앞 전의 분기 데이터보다 스무스 해졌습니다. 변동의 주기가 길어질 수록, 그래프의 형태가 스무스한 형태를 보이는 것을 알 수 있습니다.
# AirPassengers Data
AirPassengers
# 월별 자료를 분기별 자료로 변환하여 mean
air_yearly <- aggregate(AirPassengers, nfrequency = 1, FUN=mean)
par(mfrow=c(1,2))
plot(AirPassengers,xlab="Time(Monthly)",ylab="Number of passengers", main ="Airline passengers")
plot(air_yearly, xlab="Time(Yearly)", ylab='Number of Passengers', main="Airline Passengers")
생각해보기
Q. 월 → 분기 → 연도별의 순으로 자료를 변환하는 것은 가능 했다.
그렇다면, 그 역순도 가능할까?
A. 답은 아니다. 왜냐하면 시계열은 '시간의 순서에 따른 값을 변환한 것 인데, 그 역의 순으로 돌아가서 변환 한다면 이전 값에 대한 정보가 없는 상태에서 거슬러 내려간다는 것이기 때문에 불가능 하다.
과제
▶ 내장 시계열 데이터를 활용해보기
-
월별(TSA 패키지의 beersales, forecast 패키지의 wineind 데이터)
-
분기
-
연도
-
조건) aggreagte 함수 쓰기, plot 함수 사용
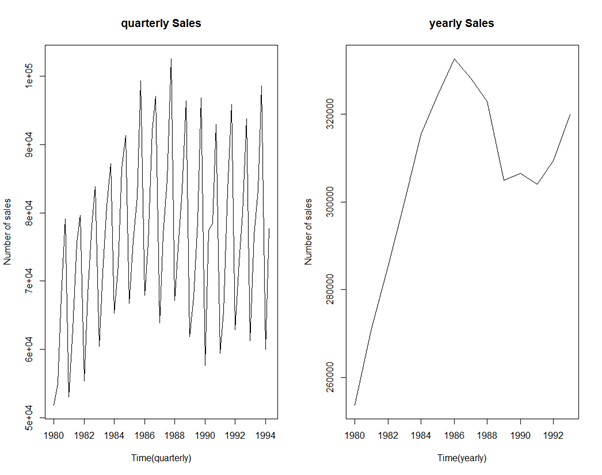
# 1. Wineind sales
wineind_quarterly <- aggregate(wineind, nfrequency = 4, FUN=sum)
wineind_yearly <- aggregate(wineind, nfrequency = 1, FUN = sum)
par(mfrow=c(1,2))
plot(wineind_quarterly,xlab="Time(quarterly)",ylab="Number of sales", main='quarterly Sales')
plot(wineind_yearly, xlab="Time(yearly)", ylab="Number of sales", main="yearly Sales")

data(beersales)beersales_quarterly <- aggregate(beersales, nfrequency = 4,FUN=sum)
beersales_yearly <- aggregate(beersales,nfrequency=1 ,FUN=sum)
par(mfrow=c(1,2))
plot(beersales_quarterly, xlab="Time(quarterly)", yalb="Number of sales", main="quarterly Sales")
plot(beersales_yearly, xlab="Time(yearly)", ylab="Number of sales", main="yearly Sales")
728x90
'Time series' 카테고리의 다른 글
| KPSS 검정 (0) | 2020.06.08 |
|---|---|
| ARIMA model & 정상성 파악 (0) | 2020.06.05 |
| 시계열의 변동요인과 모형 (0) | 2020.04.20 |
| 시계열 분석 - AirPassenger Data 등 (0) | 2020.04.03 |
| 시계열 데이터란? & 시계열의 종류 (2) | 2020.04.02 |
'Time series' Related Articles
more




Comments