
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 하계인턴
- 에이블스쿨
- 프로그래머스
- 딥러닝
- 웹크롤링
- 가나다영
- ggplot2
- 지도학습
- 머신러닝
- Eda
- ML
- httr
- 빅데이터분석기사
- kt aivle school
- SQL
- KT 에이블스쿨
- 빅분기
- 한국전자통신연구원
- 한국전자통신연구원 인턴
- 시각화
- 시계열
- 기계학습
- cnn
- Ai
- hadoop
- kaggle
- r
- SQLD
- 소셜네트워크분석
- KT AIVLE
- python
- 에이블러
- ETRI
- dx
- matplot
- 서평
- 에트리 인턴
- arima
- 하둡
- 다변량분석
Archives
- Today
- Total
소품집
시계열 분석 - AirPassenger Data 등 본문
728x90
# 시계열 데이터 분석
# Data : AirPassenger
AirPassengersR에 기본 내장되어진 AirPassengers 시계열 자료를 이용해 ts 변환을 해보려고 합니다.
먼저 데이터를 불러와 확인해봅니다.
# 시계열 데이터 인가?
is.ts(AirPassengers)
class(AirPassengers)
# 시계열 데이터 생성 (ts)
airline.ts <-ts(AirPassengers)
frequency(airline.ts) # 월 별 데이터 임을 확인
airline1.ts <- ts(AirPassengers, start = c(1949,1), frequency = 12)
airline1.ts
start(airline1.ts)
end(airline1.ts)
frequency(airline1.ts)
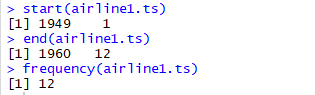
ts() 함수 -> 시계열 기본값으로 변환하여 저장하고,
반드시 start, frequency 옵션을 사용하여 시계열 데이터를 생성해줍니다. (frequency 함수 : 년/분기/월/일 데이터 타입 지정)
2. 한국은행 경제통계 시스템 (https://ecos.bok.or.kr/)
분기별 원/달러 환율 자료
setwd("C:/r_temp")
exchange.df <- read.csv("BOK_exchange_rate_krw_usd.csv")
is.ts(exchange.df)
class(exchange.df)
exchage.ts <- ts(exchange.df)
frequency(exchage.ts)
exchange1.ts <- ts(exchange.df$exchange_rate_krw_usd, start = c(1980,1), frequency = 12) # 주기:월
exchange2.ts <- ts(exchange.df$exchange_rate_krw_usd, start = c(1980,1), frequency = 4) # 4분기
3. Oil data (1994년 1년치 월별 소비량)
# Oil ts 분석
oil_user_enter.df <- read.csv("Oil_User_Enter.csv")
is.ts(oil_user_enter.df)
frequency(oil_user_enter.df)
head(oil_user_enter.df)
tail(oil_user_enter.df)
# 시계열 데이터로 변환
oil_user_enter.ts <- ts(oil_user_enter.df$oil, start = c(1994,1),frequency = 12)
is.ts(oil_user_enter.ts)
class(oil_user_enter.ts)
# oil data 1994년 1년치 월별 소비량
oil_enter_in_R <- c(8047, 7173, 8156, 6527, 6364, 6169, 6273, 6256, 6498, 7329, 8057, 9494)
is.ts(oil_enter_in_R)
class(oil_enter_in_R)
oil_enter_in_R.df <- data.frame(oil_enter_in_R)
oil_user_enter.ts <- ts(oil_enter_in_R.df, start = c(1994,1), frequency = 12)
is.ts(oil_user_enter.ts)
class(oil_user_enter.ts)
# csv 로 저장하기
write.csv(oil_user_enter.ts,"Oil_User_Enter_in_R.csv")
a <- read.csv("Oil_User_Enter_in_R.csv")
is.ts(a)
class(a) # data.frame 으로 반환 되어짐. 따라서, ts 저장시 날짜를 입력하여 저장해야 함.
date <- seq(as.Date("1994/1/1"), by="month",length.out=12)
oii_user_enter_in_R <- data.frame(date,oil_user_enter.ts)
write.csv(oil_enter_in_R,"Oil_Enter_User_in_R",row.names = F)
4. 경제 시계열 자료
# 경제 시계열 자료 (주기는 월별: frequency=12)
setwd("C:/r_temp")
economic.df <- read.csv("BOK_macro_economic_rate.csv")
is.ts(econnomic.df)
class(econnomic.df)
econominc.ts <- ts(econnomic.df[-1],start = c(2010,1), frequency = 12)
econominc.ts[,1]
econominc.ts[,2]
# 변수 별로 변환
employment.ts <- ts(economic.df$employment_rate,start=c(2010,1),frequency = 12)
bonds_3_year.ts <- ts(economic.df$bonds_3_year,start = c(2010,1),frequency = 12)
728x90
'Time series' 카테고리의 다른 글
| KPSS 검정 (0) | 2020.06.08 |
|---|---|
| ARIMA model & 정상성 파악 (0) | 2020.06.05 |
| 시계열의 변동요인과 모형 (0) | 2020.04.20 |
| 주가 시계열 자료 분석 (2) | 2020.04.07 |
| 시계열 데이터란? & 시계열의 종류 (2) | 2020.04.02 |
'Time series' Related Articles
more




Comments