
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 지도학습
- 하둡
- 한국전자통신연구원 인턴
- 웹크롤링
- 시각화
- 에이블스쿨
- 시계열
- arima
- httr
- 프로그래머스
- kt aivle school
- 소셜네트워크분석
- 하계인턴
- cnn
- 머신러닝
- r
- 다변량분석
- 에이블러
- 한국전자통신연구원
- python
- SQL
- KT 에이블스쿨
- ETRI
- 에트리 인턴
- 가나다영
- 서평
- kaggle
- 빅데이터분석기사
- hadoop
- ggplot2
- ML
- SQLD
- Eda
- KT AIVLE
- Ai
- matplot
- 빅분기
- 기계학습
- dx
- 딥러닝
Archives
- Today
- Total
소품집
[ML] Semi-Supervised Learning, K-means clustering 본문
728x90
Small Dataset, Unbalanced Dataset

Semi Supervised는 기계학습과 비지도학습의 중간 학습으로, 학습하기 전 사전에 모델에 분류를 위한 약간의 사전지식을 부여하게 됩니다.

- Transfer learning: 학습데이터가 부족한 분야의 모델 구축을 위해 데이터가 풍부한 분야에서 훈련된 모델을 재사용하게 됨 (ex: Pre-trained model의 파라메터로 초기화)
- Distant Supervision: a weakly labeled training set (training data is labeled automatically based on heuristics / rules)
- 약하게 라벨링 된 트레이닝 셋을 사용하게 됩니다. (훈련 데이터는 휴리스틱이나 규칙에 기반하여 자동적으로 라벨링 되어 있음)
- Up/down sampling
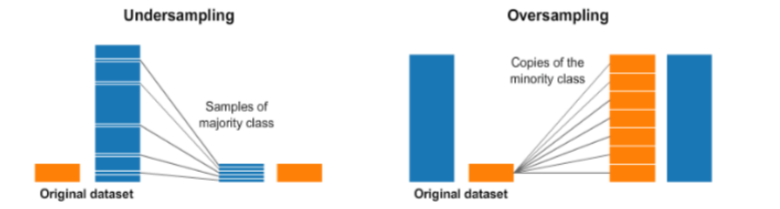
- GAN(최근 많이 화두되는 기법)을 사용하여 fake data를 생성하여 robustness를 높이기도 함
- Loss weight control
- Cost-sensitive learning: 학습 데이터의 label 비율에 반비례하게 loss 함수에 weigh를 조절함으로써, 비교적 적은 비율의 label에 해당하는 데이터에 더욱 민감하게 학습
- Focal loss: 학습 데이터 Label 비율이 높아서 상대적으로 쉽게 분류가 가능한 Label에 대한 weight를 작게 조절함으로써, Label 비율이 작은 데이터들에 집중하도록 조절 (쉽게 분류되지 않은 label에 weight를 조절!!)

Small well-known semi-supervised learning
- Active-learning
- Self-learning
- Co-learning
Active Learning

How to wisely select the data to query?
Uncertainty sampling
- 하나의 모델을 학습한 다음에 label 뿐만 아니라 confidence(확실성)가 몇 점인지 파악하고, 가장 작은 confidence를 갖는 데이터의 레이블을 물어보게 됨. 즉, 가장 애매한 것 (0.5)좀 물어볼게~
Committee-based sampling
- 학습 모델을 생성하고 학습된 모델들끼리 unlabeled data를 결정하게 되는데, 동점이 나올 때만 사람에게 물어보게 됩니다. (가장 애매한 것을 물어본다는 관점에서 Uncertainty sampling과 비슷하지만 다수결에 의해 스스로 결정한다는 점이 특별하네요.)
Self-training(self-leaning)
- 학습 데이터(Gold dataset)로 Supervised 학습함으로써 생성한 모델 M을 사용하여 unlabeled instans {x1, x2, x3}에 대하여 예측결과를 {y1, y2, y3,..}을 얻음
- Confidence가 높은 일부(Silver dataset)를 학습용으로 사용하여 모델 M'(=G+S)을 얻음
- 위 과정을 일정조건을 만족할 때까지 반복하게 됨
- 단점: 자칫 잘 못하면 모델이 엉뚱한 방향으로 학습될 수 있음
Co-learning
- 독힙적인 모델들이 각각 self-learning을 하되, 서로 간에 confidence가 높은 데이터를 물물교환 하게 된다.

Cluster
- Model is trained without labels (라벨 없이 학습)
- 하지만, 가장 확실한 clustering을 하기 위해서는 label이 있어야한다.
- Some well-known clustering models
- K-means clustering
- Hierarchical clustering
- k-NN
K-means
K-means
- K개의 '군집 중심' (Cluster centrioid)
- 개념으 1957년, '후고 스테인하우스'가 소개
- 용어는 1976년 '제임스 매퀸'이 사용
K-means 알고리즘
- K 개의 군집으로 나눠주는 알고리즘
- 1957년 ' 스튜어트 로이드'가 최초 고안함
- 1982년에 컴퓨터 과학에서 적용


관측자의 관점에 따라 1,2,4개 등 다양한 의견이 나올 수 있는데요. 그래서 최적의 K를 찾기위한 알고리즘을 보겠습니다.
K-means 알고리즘의 formal 버전

K-means 알고리즘 쉬운 버전
- 임의의 k개의 cluster centriod G1-center ~ Gk-center 선택
- 각 데이터 di와 G1-center ~ Gk-center에 대한 '거리'를 계산하여, 가장 가까운 Gi로 할당 (ex:Euclidean Distance)
- cluster centriod G1-center ~ Gk-center 재계산
- 데이터가 할당된 cluster가 변경되는 경우가 없을 때 까지 2.~4. 과정을 반복
동작예시 (K=2)

다른 예시 (K=3)

- 여기서 의문이 드는 점은, 적절한 K의 기준이 애매모호하다는 것 입니다.
- 이 최적의 K값을 자동으로 알아낼 수는 없는 걸까요?
정리: K-means 알고리즘
- 알고리즘 자체는 그다지 복잡하지 않음
- 그런데, 고민해애 할 것들이 좀 남아 있음
- [심화] 최적의 K값을 자동으로 알아낼 수는 없을까?

- [심화] 알고리즘 자체가 가진 약점은 없을까?
최적의 Cluster 개수
- 관점에 따라 '최적'이라는 개념은 달라질 수 있으며 이를 결정하기 위한 연구들이 있음
- Hierarchical clustering 결과를 활용하여 최적의 개수를 짐작하기
- Rule of thumb
- Elbow method
- 여러 후보 K 값들에 대하여, Cluster들의 적절함 평가 (ex: Cluster 중심으로부터의 거리 등)
- 즉, Grid search
- 여러 후보값들에 대하여 일일이 시행해보고 관찰하는 것
- Information Criterion Approch
- 클러스터링 모델에 대해 Likelihood를 계산하여 활용
- ex) K-means의 경우에는 Gaussian Mixture Model을 활용하여 Likelihood를 계산
- 클러스터링 모델에 대해 Likelihood를 계산하여 활용
약점
- Cluster 중심 위치 '초기값'에 으해 엉터리 결과가 나올 수 있음
- ex) 구형(Normal 분포 = 2차원 이상!)이 아닌 클러스터를 찾을 때에는 부적절한 결과를 보여줌
- Cluster 초기값을 어떻게 결정할지에 대한 연구도 있음
- Outlier(이상치)에 취약
- 해결법: Outlier 제거를 위한 전처리
- 해결법: K-medoids 알고리즘
- mean을 계산하지 않고, 데이터 중에서 하나를 중심으로 사용
kNN algorithm
Instance-Based Learning (Memory-based learning = 모델은 고려하지 않고 데이터만 바라봄)
- 학습 데이터로부터 임의의 모델 파라메터를 학습하는 것이 아닌, 학습 데이터와 테스트 데이터를 직접 '비교' → Non-parametric (모델을 고려하지 않음!!)
- 학습 데이터의 label을 사용하므로 Supervised
- kNN 알고리즘도 이에 속함
K-Nearst Neighbor 알고리즘
- "내가 본 것 중에.. '그거'랑 제일 '비슷'하네!"
- "내가 봤던 사람들 유형 중.. 이런 유형이랑 제일 '비슷' 하네!"
- K: 몇 번쨰로 가까운 데이이터 까지 살펴볼지 생각해보자

예시

728x90
'AI' 카테고리의 다른 글
| [ML/DL] Ensembles model - 앙상블 모델 (Adaboost, Random forest ..) (0) | 2020.06.23 |
|---|---|
| [ML] Hierarchical Clustering - 계층적 군집 (0) | 2020.06.13 |
| [ML/DL] SVM (Support Vector Machine) (0) | 2020.05.28 |
| [ML/DL] ANN 학습: Back-propagation (역전파 알고리즘 ) (0) | 2020.05.28 |
| [ML/DL] Artificial Neural Network (인공신경망) (0) | 2020.05.11 |
'AI' Related Articles
more




Comments