
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- kt aivle school
- python
- httr
- 소셜네트워크분석
- KT AIVLE
- 딥러닝
- 하계인턴
- cnn
- 에트리 인턴
- dx
- 프로그래머스
- kaggle
- arima
- ML
- 에이블러
- KT 에이블스쿨
- 시각화
- hadoop
- 머신러닝
- 한국전자통신연구원 인턴
- SQLD
- 웹크롤링
- 빅분기
- 지도학습
- ggplot2
- 하둡
- 빅데이터분석기사
- 한국전자통신연구원
- 서평
- ETRI
- 기계학습
- 에이블스쿨
- 다변량분석
- Eda
- SQL
- r
- matplot
- 가나다영
- 시계열
- Ai
- Today
- Total
소품집
[ML/DL] Ensembles model - 앙상블 모델 (Adaboost, Random forest ..) 본문
10장 (Ensembles) Summary

앙상블은 조화, 통합을 의미합니다.
어떤 데이터의 값을 예측한다고 할 때, 보통은 하나의 모델을 사용하는데요.
이와 달리 앙상블 모델은 여러개의 모델을 학습시켜 그 모델의 예측결과를 통합하여 예측값을 높이는데에 이용됩니다.
앙상블 학습은 여러 개의 DT(Decision Tree)를 결합하여 하나의 모델을 사용했을 때 보다 더 높은 성능을 내게 학습합니다.
앙상블의 기법 중 많이 사용되는 학습방법은
- Bagging
- Boosting
- ECOC (Error-correcting output coding)
- Stacking 등이 있습니다.

부스팅 (Boosting)
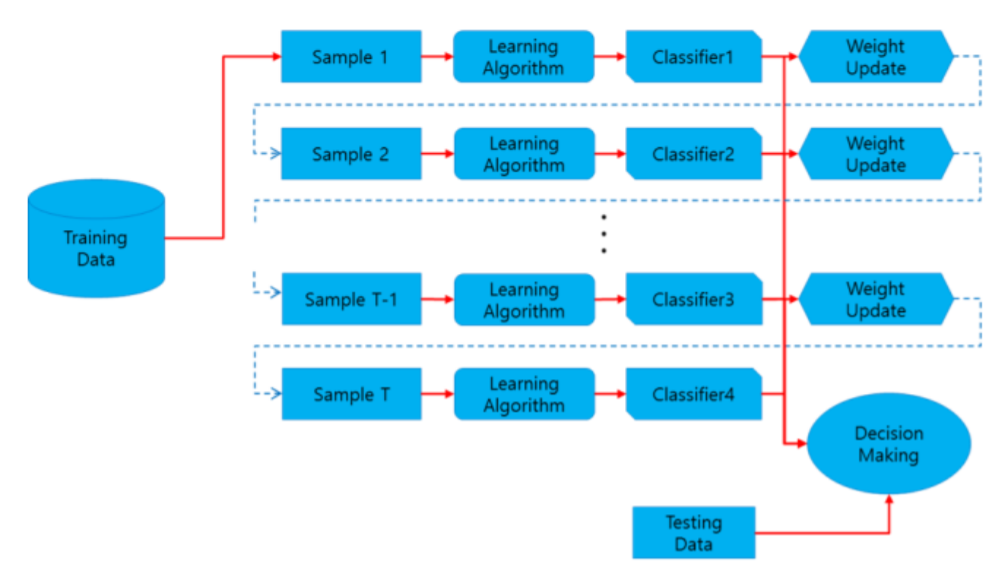
부스팅은 가중치를 활용하여 약 분류기 → 강 분류기로 학습하는 과정이 진행됩니다.
처음 모델이 예측을 하면 그 예측 결과에 따라 데이터에 가중치가 부여되고(틀리면 weigh을 크게, 맞다면 weight을 작게 조정함), 부여된 가중치가 다음 모델에 영향을 줍니다. 잘못 분류된 데이터에 집중하여 새로운 분류 규칙을 만드는 단계를 반복합니다.
기본 아이디어의 순서로 보자면,
- N: 데이터 개수, M: 모델 개수로 두면, 대부분의 경우 N>M이므로 각 모델이 몇 개의 데이터를 완벽하게 담당해준다면 모든 데이터를 커버할 수 있게됨
- 모델마다 어떤 데이터를 담당할지 여부를, 데이터에 대한 weigh로써 관리
Adaboost
학습 알고리즘

- 통합모델: h
- 녹색막대: 데이터
- 즉, 4개의 데이터
- 녹색막대의 길이 = 그 데이터의 weight
- 알고리즘 절차
- 모든 weight를 1로 초기화
- 각 h1 → h4에 대하여 순차적으로 진행되며, hi이 틀리게 예측한 데이터의 weight 증가
- 새로운 데이터 x에 대해 테스트를 할 땐, 모든 h1~h4를 대상으로 weight majority (ex: h4는 다 맞첬으므로 weight가 가장 크게 나온다.)

부스팅은 순차적으로 학습이 진행되며, 학습 결과에 따라 weight가 조정되어집니다.
즉 가중치가 다음 모델의 결과 예측에 영향을 주게됩니다.
배깅 (Bagging)
배깅이란 Bootstrap Aggregation의 약자로, 샘플을 여러번 뽑아 각 모델을 학습시켜 결과물을 Aggregation하는 방법입니다.

- 학습 데이터 중에서 Bootstrap(복원 샘플링)하여 여러 bag에 나눠 갖음
- 복원샘플링 → 각 learner 들이 ‘독립적‘으로 학습되게 하여, 생성된 bag에 대해 각각 별도의 model을 학습하게 됨
- 테스트 시, 학습된 여러 모델들에 대하여, uniform voting(aggregation) 기반으로 결과값 생성
++
Categorical Data는 투표 방식(Votinig)으로 결과를 집계하며, Continuous Data는 평균으로 집계합니다.
Categorical Data일 때, 투표 방식으로 한다는 것은 전체 모델에서 예측한 값 중 가장 많은 값을 최종 예측값으로 선정한다는 것입니다. 6개의 결정 트리 모델이 있다고 합시다. 4개는 A로 예측했고, 2개는 B로 예측했다면 투표에 의해 4개의 모델이 선택한 A를 최종 결과로 예측한다는 것입니다.
평균으로 집계한다는 것은 말 그대로 각각의 결정 트리 모델이 예측한 값에 평균을 취해 최종 Bagging Model의 예측값을 결정한다는 것입니다. 배깅 기법을 활용한 모델이 바로 랜덤 포레스트입니다.
sorce
https://bkshin.tistory.com/entry/머신러닝-11-앙상블-학습-Ensemble-Learning-배깅Bagging과-부스팅Boosting
Random Forest
Decision Tree

- Root node → Leaf node 방향으로 임의의 feature를 고려해가며, 데이터들이 분류되어짐
- 데이터가 다르면, 생성되는 Tree 또한 다르다.
Random Forest
- Random: 임의, 무작위
- Forest: 숲, (많은 Tree)
- → 무작위의 많은 Tree들
- N개의 학습데이터 D1:N에 대하여 'Bagging'으로 K개의 Bag 생성
- 각 Bag에 대하여 Decision Tree 학습
- 즉, K개의 Tree가 생성됨 (→ forest)
- 테스트 데이터 X에 대하여, 학습된 Tree들로부터 voting 방식을 통해 결과값 예측

단순히 Tree가 여러 개 생성되었기 때문에 더 좋은 결과가 나오는 것일까? Random forest의 성능이 매우 좋은 이유는 무엇일까?
- Decision Tree 한계
- Bias는 작고 Variance는 크다
- 즉, noise에 민감
- 트리가 커지게 되면 overfitting 가능성이 큼
- Random Forest
- Bagging 과정은 각 Tree의 bias는 유지하면서 variance는 작게 만듬
- 각 Tree는 서로 독립적으로 학습되었으므로, 통합된 의사결정시 noise에 강해지게됨
Random Forest 생성을 위해 bagging이 이용되는 것을 봤는데, 이외에도 '임의노드 최적화 방법'이라는 것을 통해 Random forest의 randomness를 강화하기도 한다고 한다. 이것에 대해 찾아보자.
배깅과 부스팅의 차이
- 부스팅의 가장 큰 특징은 다음 단계의 weak classifier가 이전 단계의 weak classifier의 영향을 받음
- 배깅은 복원샘플링 → 각 learner 들이 독립적으로 학습되게 함

위 그림에서 나타내는 바와 같이 배깅은 병렬로 학습하는 반면, 부스팅은 순차적으로 학습합니다. 한번 학습이 끝난 후 결과에 따라 가중치를 부여합니다. 그렇게 부여된 가중치가 다음 모델의 결과 예측에 영향을 줍니다.
오답에 대해서는 높은 가중치를 부여하고, 정답에 대해서는 낮은 가중치를 부여합니다. 따라서 오답을 정답으로 맞추기 위해 오답에 더 집중할 수 있게 되는 것입니다.
부스팅은 배깅에 비해 error가 적습니다. 즉, 성능이 좋습니다. 하지만 속도가 느리고 오버 피팅이 될 가능성이 있습니다. 그렇다면 실제 사용할 때는 배깅과 부스팅 중 어떤 것을 선택해야 할까요? 상황에 따라 다르다고 할 수 있습니다. 개별 결정 트리의 낮은 성능이 문제라면 부스팅이 적합하고, 오버 피팅이 문제라면 배깅이 적합합니다.
'AI' 카테고리의 다른 글
| [Kaggle] Airbnb Data시각화 및 regression (1) (0) | 2020.08.26 |
|---|---|
| [ML/DL] Topic modeling, LDA (0) | 2020.06.24 |
| [ML] Hierarchical Clustering - 계층적 군집 (0) | 2020.06.13 |
| [ML] Semi-Supervised Learning, K-means clustering (0) | 2020.06.13 |
| [ML/DL] SVM (Support Vector Machine) (0) | 2020.05.28 |


