
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 빅데이터분석기사
- python
- KT AIVLE
- 기계학습
- 웹크롤링
- ETRI
- kaggle
- 시계열
- 지도학습
- 프로그래머스
- dx
- Eda
- 한국전자통신연구원 인턴
- hadoop
- 한국전자통신연구원
- SQL
- 빅분기
- 가나다영
- 시각화
- httr
- kt aivle school
- SQLD
- 에이블러
- 머신러닝
- KT 에이블스쿨
- 다변량분석
- Ai
- ML
- matplot
- r
- 서평
- 에이블스쿨
- arima
- ggplot2
- 하둡
- 소셜네트워크분석
- 딥러닝
- cnn
- 에트리 인턴
- 하계인턴
- Today
- Total
소품집
[KT AIVLE] ML/DL 모델링 전 알아야 할 도메인 본문

데이터 분석 프로세스

1. 비즈니스 이해
- 문제 정의 (따릉이 배치 장소를 추가하자)
- 데이터 분석 방향, 목표 설정 (따릉이 수요와 공급이 맞는 장소에 배치를 늘린다)
- 가설 수립 (따릉이 대여량은 따릉이 배치 시설과 관련이 있다)
2. 데이터 이해
- EDA & CDA
- 데이터 통계량 확인
3. 데이터 전처리
- 결측치 확인 (대치, 삭제, 변환 등)
- 가변수화 (범주 > 수치)
- 스케일링 * 표준화, 정규화
- 데이터 분할 (train, validation)
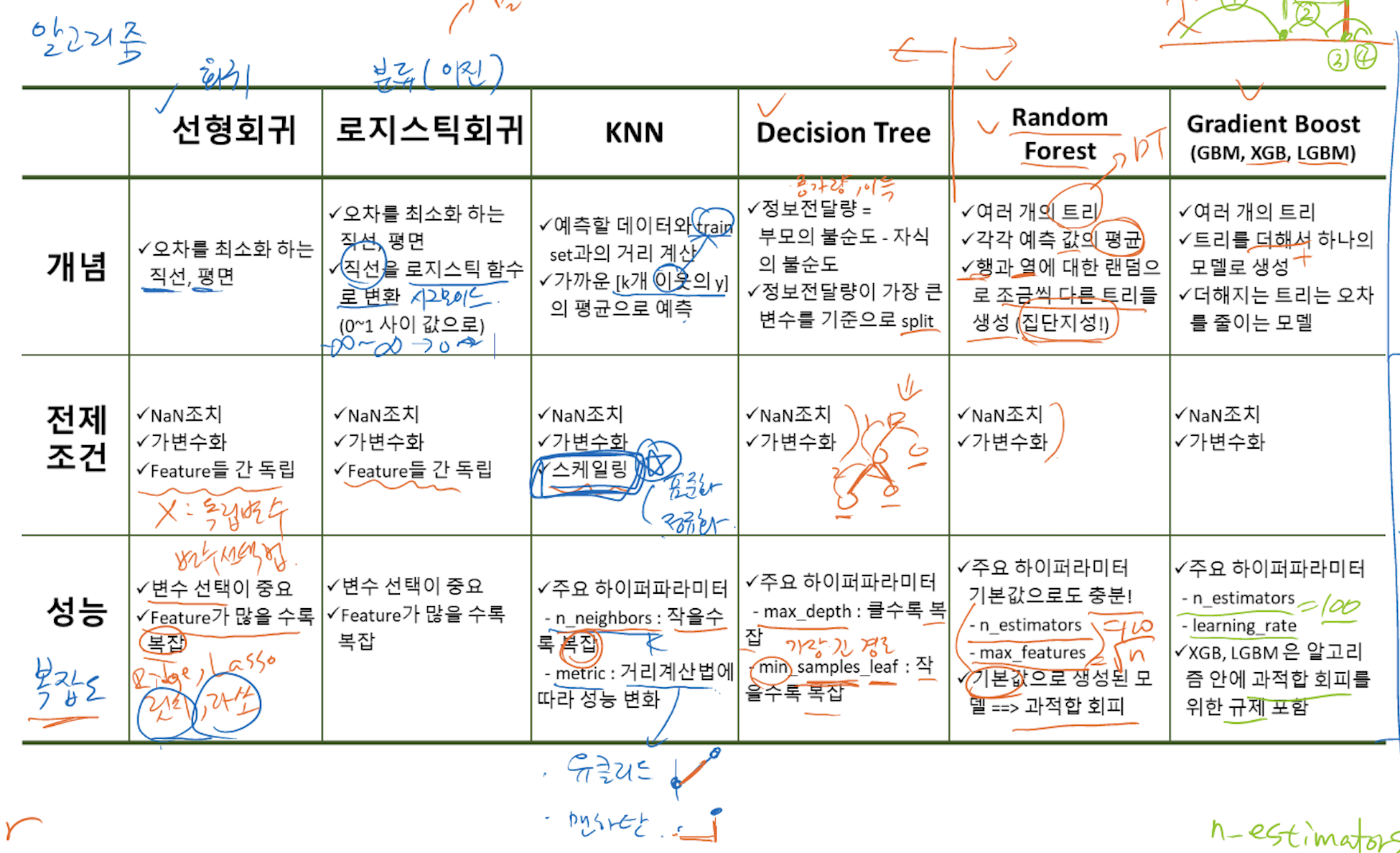
4. 모델링
- 분류 > logistic, Naive bayes, DT, SVM, catboost, ensemble..
- 회귀 > liner, Gradient desent, ridge, lasso..
- 모델 학습
- 검증 및 평가
1) classification
positive(1) 입장에서 보자.
- accuracy = (TP+TN) = (TP+TN+FP+FN)
- recall = TN/(FP+TN)
- precision = TP/(TP+FP)
- f-1 score = recall과 precision의 조화 평균
* 비즈니스 관점에서 각 중요한 평가 요소가 있음.
ex) 공장에서 불량을 점검할 때 recall 이 더 중요 > 비용 절감, 불량품 특징 추출 등 비즈니스 관점에서 이득임

2) regression
- R^2 = SSR/SST = 1-(SSE/SST)

- MAE, MSE, RMSE

5. 최종 평가
- 위 평가 지표를 기반으로 비즈니스를 얼마나 잘 설명하는지 평가할 수 있다.
모델링
https://sodayeong.tistory.com/32
- 모델 파라미터 옵션 조정 참조
ANN 학습: Back-propagation (역전파 알고리즘 )
2020/05/11 - [Data mining] - Artificial Neural Network (인공신경망) Artificial Neural Network (인공신경망) Neural Network Motivated by studies of the brain (사람의 뇌를 학습한 모습!) A network of "a..
sodayeong.tistory.com

강사님께서 딥러닝 모델링을 들어가기 전 지금까지 배운 모~든 과정을 짚어주셔서 정리해보았습니다.
전공이고, 배운 내용이지만 정리해야 더 기억이 잘 되는 건! 확실합니다... ㅎㅎ
'AI > KT 에이블스쿨' 카테고리의 다른 글
| [KT AIVLE] Deep learning - ANN, CNN (1) | 2022.09.20 |
|---|---|
| [KT AIVLE] keras Sequential model - DL 기본 (0) | 2022.09.17 |
| [KT AIVLE] 머신러닝 앙상블 모델 - 보팅, 배깅, 부스팅 (0) | 2022.09.14 |
| [KT AIVLE] KT 에이블스쿨 에이블데이 리뷰!! (0) | 2022.09.12 |
| [KT AIVLE] 에이블스쿨 DX 스터디 (코테, 데분 등!) (2) | 2022.09.02 |



