
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 소셜네트워크분석
- SQL
- 가나다영
- 에이블러
- hadoop
- 딥러닝
- ETRI
- ggplot2
- KT 에이블스쿨
- kaggle
- 빅분기
- 머신러닝
- cnn
- SQLD
- 한국전자통신연구원 인턴
- 시계열
- ML
- r
- 시각화
- 한국전자통신연구원
- httr
- 기계학습
- 다변량분석
- 에트리 인턴
- arima
- 빅데이터분석기사
- 하계인턴
- Eda
- kt aivle school
- 프로그래머스
- 서평
- matplot
- 에이블스쿨
- 웹크롤링
- python
- 지도학습
- Ai
- KT AIVLE
- 하둡
- dx
- Today
- Total
소품집
[KT AIVLE] 머신러닝 앙상블 모델 - 보팅, 배깅, 부스팅 본문
앙상블

앙상블은 여러 분류기의 결과를 하나로 합치며 모델을 통합하는 것과 같고, 여러 개의 DT를 결합하며 하나의 모델을 사용했을 때 보다 더 높은 성능을 낼 수 있도록 한다. 앙상블 기법 중 많이 사용되는 학습 방법으로는 Voting, Bagging, Boosting, ECOC (Error-correcting output coding), Stacking 등이 있다.
1. 보팅 (voting)
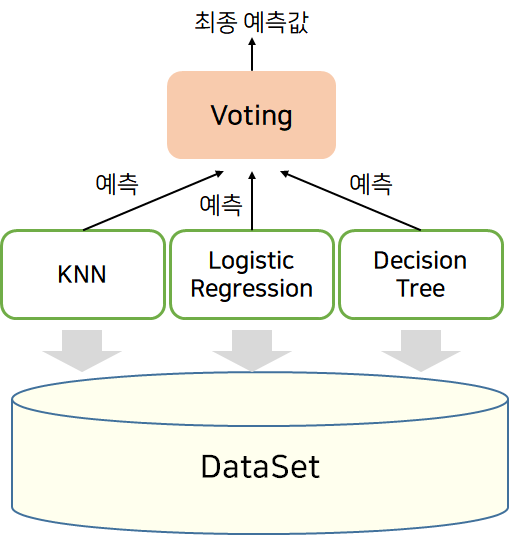
일반적으로 보팅은 여러 가지 머신러닝 모델(여기에선 KNN, Logistic Regression, DT)을 같은 데이터 셋에 대하여 학습시킨 뒤, 예측한 결과를 투표하여 최종 결과로 선정하는 방식으로 진행된다. 보팅 방식에도 소프트 보팅과 하드 보팅으로 나뉜다.
- 하드보팅 : 다수결 투표와 동일한 개념. 이 경우 predict 메소드를 사용하여 최종 예측 클래스만 리턴 받고, 가장 많이 보팅 받은 클래스를 최종 클래스로 결정된다.
- 소프트부팅 : 최종 아웃풋 결과를 확률 값으로 평균 낸 뒤, 가장 높은 확률로 최종 클래스로 결정한다.
일반적으로는 소프트부팅을 많이 사용하며, 이를 적용한 예제를 보자.
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, cross_val_score
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns = cancer.feature_names)
# 데이터를 훈련셋과 테스트셋으로 나누기
x_train, x_test, y_train, y_test = train_test_split(cancer.data,cancer.target,test_size=0.3,random_state=2022)
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import *
log_model = LogisticRegression()
knn_model = KNeighborsClassifier()
estimators = [('log_model', LogisticRegression()),
('knn', KNeighborsClassifier(n_neighbors=5))]
model = VotingClassifier(estimators=estimators, voting='soft')
model.fit(x_train, y_train) # 학습
y_pred = model.predict(x_test) #예측
# confusion matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
soft voting으로 진행했다. 이 경우에는 각 모델(KNN, Logistic)은 0~1까지 확률 값을 리턴하게 되고, 각 확률 값의 평균을 취해 가장 높은 평균을 가진 클래스로 예측을 하게 된다.
2. 배깅 (bagging)

배깅은 boostrap aggregating의 줄임으로 보팅과 다르게 단일 모델만을 사용한다. 단일 모델을 다른 데이터로 학습시켜 결과를 결합하고, 전체 데이터 셋 중 랜덤 샘플링을 통해 얻은 여러 개의 subset(복원 추출)을 각각 모델이 취해 학습을 진행하게 된다.

배깅을 도메인으로 둔 알고리즘은 랜덤 포레스트로, DT 다수개의 모델을 결합해 부트스트랩으로 예측치를 결합한다.
이때, 범주형 데이터는 보팅(voting)을 연속형 데이터는 평균으로 반환하게 된다.
복원 샘플링 시 각 leaner 들은 '독립적'으로 학습하게 되며 각 별도의 model을 학습하게 된다.
* 부트스트랩 : 중복을 허용한 리샘플링
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
x, y = make_moons(n_samples=500, noise=0.30, random_state=2022)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=2022)
bag_model = BaggingClassifier(DecisionTreeClassifier(),n_estimators=500, max_samples=100, bootstrap=True, n_jobs=-1)
bag_model.fit(x_train, y_train)
y_pred = bag_model.predict(x_test)
accuracy_score(y_test, y_pred) # oob_score = False > 0.88
bag_model2 = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True, n_jobs=-1, oob_score=True)
bag_model2.fit(x_train, y_train)
y_pred = bag_model2.predict(x_test)
bag_model2.oob_score_ # oob_score=True > 0.90oob(out of bag) 평가
일반적으로 훈련할 때 사용하는 데이터는 63% 정도이다. 나머지 37%는 oob(out of bag)라고 부릅니다. 훈련할 때 이 데이터를 사용하지 않으므로 마지막 테스트 데이터로 이용할 수 있습니다. oob_score=True로 해주면 훈련이 끝나는 후 자동으로 oob 평가를 수행합니다.
출처: https://hoony-gunputer.tistory.com/144 [후니의 컴퓨터:티스토리]
3. 부스팅 (boosting)

부스팅은 순차적으로 학습이 진행되며, 이전 모델에서 분류하지 못한 feature에 대해 가중치가 부여돼 다음 모델 결과에 영향을 주며 강 분류기로 학습되는 방식이다.
전공으로 머신러닝 수강했을 때 로깅해 둔 거 많이 참조했다.
근본은 안 변하는데 계속 까먹는당...ㅎ ;
https://sodayeong.tistory.com/49
Ensembles model - 앙상블 모델 (Adaboost, Random forest ..)
10장 (Ensembles) Summary 앙상블은 조화, 통합을 의미합니다. 어떤 데이터의 값을 예측한다고 할 때, 보통은 하나의 모델을 사용하는데요. 이와 달리 앙상블 모델은 여러개의 모델을 학습시켜 그 모델
sodayeong.tistory.com
'AI > KT 에이블스쿨' 카테고리의 다른 글
| [KT AIVLE] keras Sequential model - DL 기본 (0) | 2022.09.17 |
|---|---|
| [KT AIVLE] ML/DL 모델링 전 알아야 할 도메인 (0) | 2022.09.14 |
| [KT AIVLE] KT 에이블스쿨 에이블데이 리뷰!! (0) | 2022.09.12 |
| [KT AIVLE] 에이블스쿨 DX 스터디 (코테, 데분 등!) (2) | 2022.09.02 |
| [KT AIVLE] Scikti learn 라이브러리로 ML 모델 입문 (0) | 2022.08.31 |



