
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 웹크롤링
- matplot
- 시계열
- cnn
- httr
- r
- ggplot2
- arima
- 빅분기
- 소셜네트워크분석
- 에이블스쿨
- 머신러닝
- hadoop
- dx
- 하계인턴
- python
- KT AIVLE
- 에트리 인턴
- kt aivle school
- 시각화
- 딥러닝
- ETRI
- 에이블러
- 한국전자통신연구원 인턴
- 다변량분석
- Ai
- SQL
- SQLD
- 서평
- Eda
- KT 에이블스쿨
- 빅데이터분석기사
- kaggle
- 한국전자통신연구원
- ML
- 기계학습
- 가나다영
- 프로그래머스
- 지도학습
- 하둡
- Today
- Total
목록AI (94)
소품집
 [Kaggle] 올림픽 데이터를 활용한 EDA
[Kaggle] 올림픽 데이터를 활용한 EDA
dplyr 패키지 연습 겸 EDA 연습 겸 getwd() setwd('/Users/dayeong/Desktop/reserch/data') library(dplyr) library(ggplot2) # 0. Data load 및 이전 시험 진행과정 athlete % arrange(desc(mean_height)) head(survey) # Step2. 위의 나온 결과물을 활용해 해당하는 team만 뽑고, # Team별로 가장 키가 큰 사람과 가장 작은 사람의 키, 두 키의 차이를 출력 team % group_by(Team) %>% summarise(max_hei = max(Height), min_hei = min(Height), dif = max(Height)- min(Height)) head(survey2..
 [Kaggle] BlackFriday 데이터를 활용한 EDA (5)
[Kaggle] BlackFriday 데이터를 활용한 EDA (5)
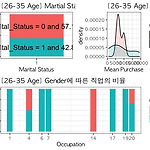
setwd('/Users/dayeong/Desktop/reserch/data') # Dataloading dt_loan % mutate(buy_n = n()) %>% filter(buy_n>=600) # 중복 제거 dt 이 Age 고객들을 분석해보자 Age_25 % filter( Age == "26-35" ) Age_25 % mutate(ratio = n/sum(n), location = ifelse(ratio > min(ratio) , min(ratio) + ratio/2 , ratio/2 ) ) plot1 % ggplot(aes(x=factor(1), y = ratio, fill = Marital_Status)) + geom_bar(stat="identity") + geom_text(aes(x= fa..
 [Kaggle] 채무 불이행자
[Kaggle] 채무 불이행자
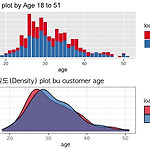
모델링 부터 오류가 나서 (아직 해결치 못함 ..) 그 전의 code까지 업뎃 해둡니다. ㅠ ㅠ getwd() setwd('/Users/dayeong/Desktop/reserch/data') Encoding('UTF-8') # Kaggle - DAY4 # Kaggle Loan data binary classification # Data import library(readr) # Data input with readr::read_csv() # EDA : 탐색적 데이터 분석, 데이터 확인 library(VIM) # Missing values with VIM::aggr() library(descr) # descr::CrossTable() - Factor data의 범주별 빈도수, 비율 확인 library(DT..
 [Kaggle] 채무 불이행자 searching - ing (4)
[Kaggle] 채무 불이행자 searching - ing (4)
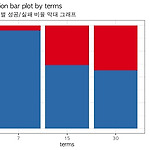
getwd() setwd('/Users/dayeong/Desktop/reserch/data') Encoding('UTF-8') # Kaggle - DAY4 # Kaggle Loan data binary classification # Data import library(readr) # Data input with readr::read_csv() # EDA : 탐색적 데이터 분석, 데이터 확인 library(VIM) # Missing values with VIM::aggr() library(descr) # descr::CrossTable() - Factor data의 범주별 빈도수, 비율 확인 library(DT) # DT::datatable() - All data assesment with web char..
www.kaggle.com/frankmollard/interactive-visualizations Interactive Visualizations 🚢 Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic: Machine Learning from Disaster www.kaggle.com 지금까지 본 R 시각화 중에 젤 보기 쉽고,,, 예쁜듯 👍🏻
 [Kaggle] House prices 예측 (3) - 오늘은 실패
[Kaggle] House prices 예측 (3) - 오늘은 실패
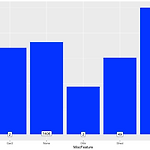
오늘은 .. 수준보다 높은 kaggle notebook을 택한 탓인지 진행이 잘 안되어 다음번에 다시 도저어어언 + ggolot2 option은 진짜 다양해서 그때마다 필요한 거 구글링 하는 게 최고옹 getwd() setwd('/Users/dayeong/Desktop/reserch/data') # Kaggle 3DAY # https://www.kaggle.com/erikbruin/house-prices-lasso-xgboost-and-a-detailed-eda # House prices : Laso, XGBoost, and a detailed EDA # 주택 임대가격 예측하여 최종 가격 예측하기! # # Loading and Exploring Data library(knitr) library(ggplo..
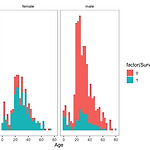 [Kaggle] Titanic 시각화 및 prediction (2)
[Kaggle] Titanic 시각화 및 prediction (2)
오늘은 kaggle 타이타닉 데이터 셋을 이용해 시각화와 예측을 해봤다. getwd() setwd('/Users/dayeong/Desktop/reserch/data') # Kaggle 2DAY # https://www.kaggle.com/mrisdal/exploring-survival-on-the-titanic # Load packages library(ggplot2) library(ggthemes) library(scales) library(dplyr) library(mice) library(randomForest) # classification model ## # Load Data train
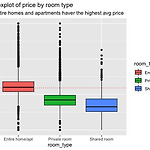 [Kaggle] Airbnb Data시각화 및 regression (1)
[Kaggle] Airbnb Data시각화 및 regression (1)
1일 1캐글 하깅 로깅하깅 getwd() setwd('/Users/dayeong/Desktop/reserch/data') # kaggle 1DAY # https://www.kaggle.com/josipdomazet/mining-nyc-airbnb-data-using-r library(tidyverse) library(ggthemes) library(GGally) library(ggExtra) library(caret) library(glmnet) library(corrplot) library(leaflet) library(kableExtra) library(RColorBrewer) library(plotly) library(ggplot2) library(knitr) # 간단하게 데이터 프레임 생성이 가능..
진짜 어렵당 https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/06/01/LDA/ Topic Modeling, LDA · ratsgo's blog 이번 글에서는 말뭉치로부터 토픽을 추출하는 토픽모델링(Topic Modeling) 기법 가운데 하나인 잠재디리클레할당(Latent Dirichlet Allocation, LDA)에 대해 살펴보도록 하겠습니다. 이번 글 역시 고려대 강�� ratsgo.github.io