
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- SQLD
- 딥러닝
- 에이블스쿨
- 서평
- 시각화
- dx
- 웹크롤링
- arima
- 프로그래머스
- ML
- 시계열
- cnn
- hadoop
- httr
- ETRI
- 머신러닝
- 지도학습
- SQL
- 기계학습
- kaggle
- KT 에이블스쿨
- 빅데이터분석기사
- r
- 하계인턴
- ggplot2
- matplot
- 가나다영
- 빅분기
- 에트리 인턴
- python
- 한국전자통신연구원 인턴
- Ai
- Eda
- 소셜네트워크분석
- kt aivle school
- 한국전자통신연구원
- 에이블러
- 하둡
- 다변량분석
- KT AIVLE
- Today
- Total
소품집
[KT AIVLE] Scikti learn 라이브러리로 ML 모델 입문 본문

사이킷런(sklearn)
- 파이썬에서 머신러닝 모델을 돌릴 때 유용하게 사용할 수 있는 라이브러리
- 여러 가지 머신러닝 모듈로 이루어져 있음.
모듈 불러오기
- 자주 사용되는 모듈을 불러오자
import numpy as np ## 기초 수학 연산 및 행렬계산
import pandas as pd ## 데이터프레임 사용
import seaborn as sns ## plot 그릴때 사용
import matplotlib.pyplot as plt ## plot 그릴때 사용
from sklearn import datasets ## iris와 같은 내장 데이터 사용
from sklearn.model_selection import train_test_split ## train, test 데이터 분할
from sklearn.linear_model import LinearRegression ## 선형 회귀분석
from sklearn.linear_model import LogisticRegression ## 로지스틱 회귀분석
from sklearn.naive_bayes import GaussianNB ## 나이브 베이즈
from sklearn import svm ## 서포트 벡터 머신
from sklearn import tree ## 의사결정나무
from sklearn.ensemble import RandomForestClassifier ## 랜덤포레스트
데이터 불러오기
- 기본 내장 데이터인 유방암 진단 데이터 (classification)
raw = datasets.load_breast_cancer() # 유방암 데이터
print(raw.feature_names) #
data = pd.DataFrame(raw.data)
target = pd.DataFrame(raw.target)
rawData = pd.concat([data, target], axis=1)
## 열(column)이름 설정
rawData.columns=['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error', 'fractal dimension error',
'worst radius', 'worst texture', 'worst perimeter', 'worst area',
'worst smoothness', 'worst compactness', 'worst concavity',
'worst concave points', 'worst symmetry', 'worst fractal dimension'
, 'cancer']
rawData.head()
train, test 데이터 셋 분할
- 주어진 전체 데이터를 모델에 바로 적용하는 게 아니라, 데이터 셋을 분할하여 학습하게 해 오버 피팅을 방지한다.
target='cancer'
x = rawData.drop(target, axis=1)
y = rawData[target]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)test_size : test 셋 비율
train_size : train 셋 비율 (default로 test_size만 넣어줘도 됨.)
random_state : 랜덤 시드 번호
surffle : 데이터 셔플링
사이킷런 모델 적용
1. Logistic Regression
- 로지스틱 회귀 모델은 선형 회귀와 유사하며 대상 변수가 이진류로 1/0으로 분류하게 된다.

model = LogisticRegression()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(confusion_matrix(y_test, y_pred))
print('='*55)
print(classification_report(y_test, y_pred))

2. Decision Tree
https://sodayeong.tistory.com/9
Decision Tree (의사결정 나무)
Decision Tree Decision tree는 머신러닝 중에서도 대표적인 지도 학습에 속합니다. 지도 학습이란, 모델 학습을 위해 '정답'이 주어진 데이터를 classification 하도록 만든 일종의 러닝 기술입니다. 즉 무
sodayeong.tistory.com
- 가장 잘 나눠주는 feature로 분기하게 되며 information gain 이 가장 큰 feature 선택한다.
model = DecisionTreeClassifier()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(confusion_matrix(y_test, y_pred))
print('='*55)
print(classification_report(y_test, y_pred))

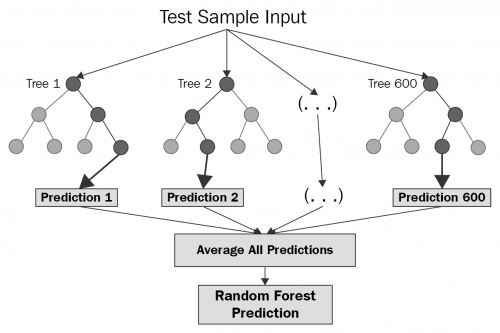
3. RandomForest
- 앙상블 모델로, 여러 개의 트리 모델을 병합하여 평균 예측치를 출력하며 동작함.
model = RandomForestClassifier(max_depth=2, random_state=0)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(confusion_matrix(y_test, y_pred))
print('='*55)
print(classification_report(y_test, y_pred))
* 본 포스팅은 KT 에이블 스쿨 저작권을 침해하지 않았습니다.
'AI > KT 에이블스쿨' 카테고리의 다른 글
| [KT AIVLE] KT 에이블스쿨 에이블데이 리뷰!! (0) | 2022.09.12 |
|---|---|
| [KT AIVLE] 에이블스쿨 DX 스터디 (코테, 데분 등!) (2) | 2022.09.02 |
| [KT AIVLE] Git 파일 버전 관리 기본 (0) | 2022.08.29 |
| [KT AIVLE] 에이블스쿨 미니프로젝트 2차 회고 (0) | 2022.08.24 |
| [KT AIVLE] 에이블스쿨 게더타운 이벤트!! + 지역 1등 수상..💙 (0) | 2022.08.18 |



